Ruimtelijke analyse
Grid Viewer 1.2
Grid Viewer geeft in de legenda de mogelijkheid om uw data ruimtelijk te analyseren.
Structuren ontdekken
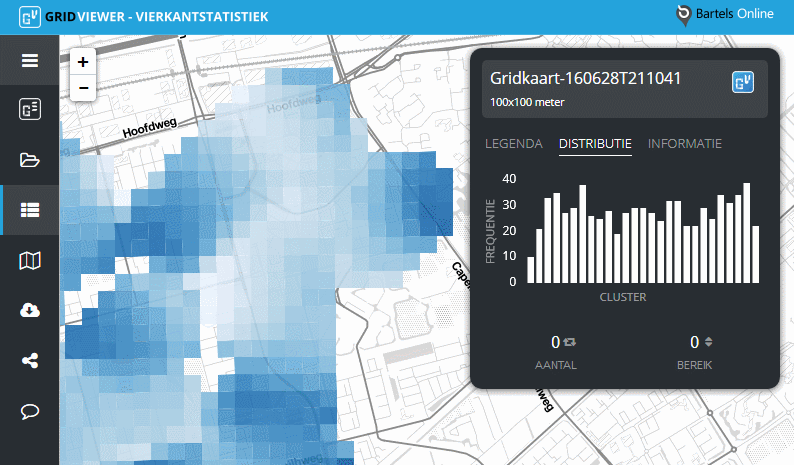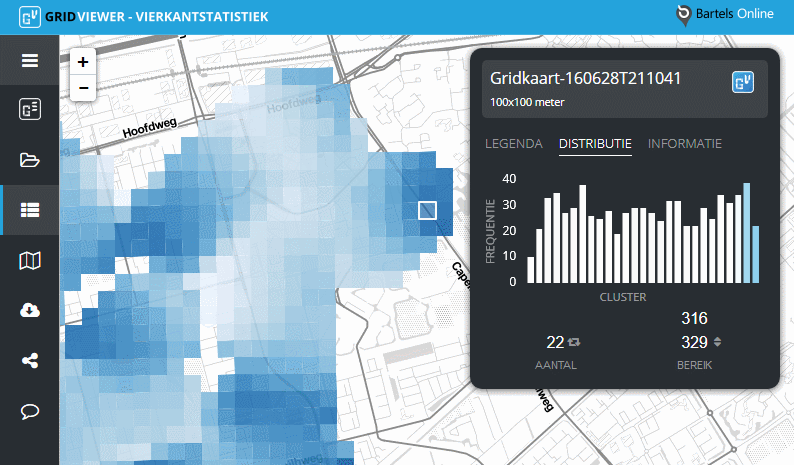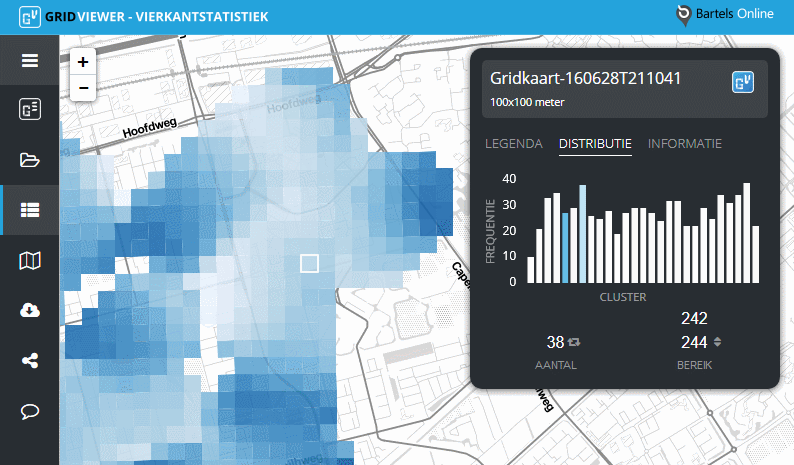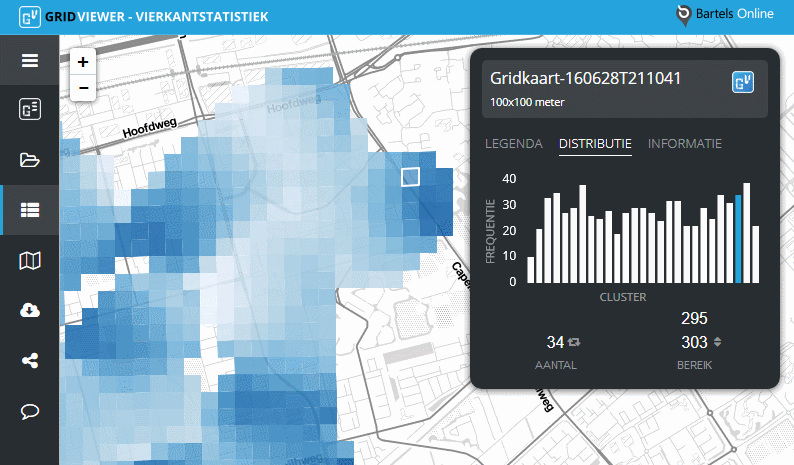
De legenda bevat een tabblad Distributie. Deze toont een gecategoriseerde weergave van de uitkomsten van de berekening voor de huidige gridkaart. Dat wil zeggen: de numerieke uitkomsten zijn omgezet naar categorische data om zo structuren in de data te kunnen ontdekken.
Zijn er bijvoorbeeld veel resultaten dicht in de buurt van de maxima en/of minima? Hoe ziet de distributie (frequentie) van de data eruit? Welke relaties bestaan er in de data?
Onderstaand figuur laat zien hoe u op basis van gecategoriseerde data deze vragen kunt beantwoorden.
Beweeg met de muisaanwijzer over een vierkant om te zien in welke categorie, of cluster, de waarde van het betreffende vierkant valt.
Figuur 1: Gecategoriseerde data helpt u om structuren te ontdekken
Distributiegrafiek
De dataset van de gridkaart wordt door een algoritme in een aantal categoriëen verdeeld (clusters). Deze clusters staan op de horizontale as van figuur 1. De verticale as toont het aantal malen van voorkomen van een data-element in het betreffende cluster (frequentie).
Per cluster wordt het aantal data-elementen getoond, inclusief het bereik van die elementen in het cluster.
Gebruikt algoritme
Het clustering-algoritme dat gebruikt wordt, is het K-means algoritme. Dit algoritme deelt een dataset op in groepen met vergelijkbare kenmerken. Elke groep is vertegenwoordigd door zijn zwaartepunt (het gewogen gemiddelde van die punten) en houdt rekening met natuurlijke onderbrekingen in de data.
Deze groepen zijn handig voor het verkennen van de gegevens in de dataset, het identificeren van afwijkingen in de gegevens, of helpen bij het identificeren van relaties in een dataset die misschien niet logisch zijn af te leiden door eenvoudige observatie.
Verwante onderwerpen
Laatst gewijzigd: 2018-10-18